Lec 6 Implementing Deep Reinforcement Learning SNNs with BrainCog
This document introduces how to use the basic modules provided by BrainCog to realize the application of brain-inspired spiking neural network in deep reinforcement learning. Using the LIF neuron model integrated by BrainCog and the backprop training method based on surrogate gradient function, we successfully applied the Spiking-DQN network model on Atari game tasks.
Basic Modules of BrainCog
Neuron Model
Spiking-DQN consists of a three-layer spiking convolutional neural network and a two-layer fully connected spiking neural network. LIF neurons are used as the basic information processing unit in the network:
class LIFNode(BaseNode):
def __init__(self, threshold=0.5, tau=2., act_fun=QGateGrad, *args, **kwargs):
super().__init__(threshold, *args, **kwargs)
self.tau = tau
if isinstance(act_fun, str):
act_fun = eval(act_fun)
self.act_fun = act_fun(alpha=2., requires_grad=False)
Spiking CNN is responsible for processing the visual image input of the game environment, and the output layer spikes are weighted and averaged to generate action selection signals to interact with the environment.
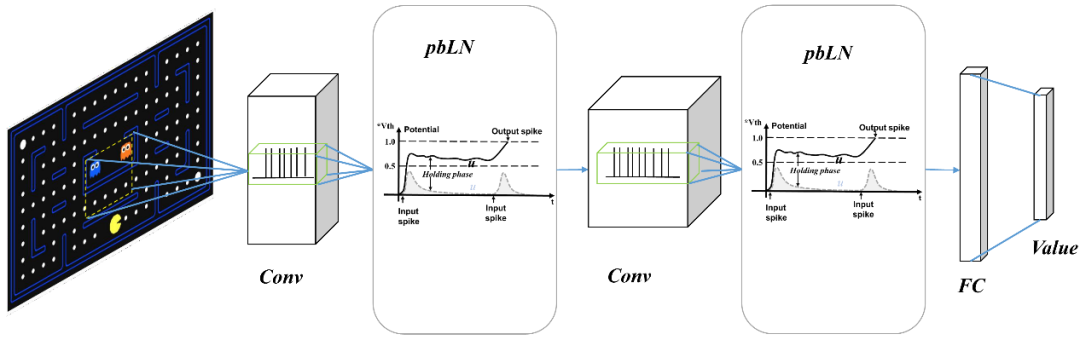
Use the LIF neuron model packaged by BrainCog to build a Spiking-DQN network model:
class SpikingDQN(nn.Module):
def __init__(self,c: int,h: int,w: int, action_shape: Sequence[int],
device: Union[str, int, torch.device] = "cpu",time_window: int = 16,features_only: bool = False,
) -> None:
super().__init__()
self._node = LIFNode
The spiking convolutional neural network uses the same network structure as DQN:
self.net = nn.Sequential(
nn.Conv2d(c, 32, kernel_size=8, stride=4),
PopNorm([32, 20, 20], threshold=self._threshold, v_reset=self.v_reset),
self._node(threshold=self._threshold, v_reset=self.v_reset),
nn.Conv2d(32, 64, kernel_size=4, stride=2),
PopNorm([64, 9, 9], threshold=self._threshold, v_reset=self.v_reset),
self._node(threshold=self._threshold, v_reset=self.v_reset),
nn.Conv2d(64, 64, kernel_size=3, stride=1),
PopNorm([64, 7, 7], threshold=self._threshold, v_reset=self.v_reset),
self._node(threshold=self._threshold, v_reset=self.v_reset),
nn.Flatten()
)
Spiking CNN encodes the visual input into the spike sequence, and outputs the action selection signal corresponding to the state through the fully connected spike neural network processing:
self.net = nn.Sequential(
self.net, nn.Linear(self.output_dim, 512),
self._node(threshold=self._threshold, v_reset=self.v_reset),
nn.Linear(512, np.prod(action_shape), bias=False)
)
Membrane potential normalization solves the problem of spike signal disappearance in deep SNN
Because of the complex dynamic characteristics of spiking neurons and the highly nonlinear process of SNN, the input spike signal is difficult to propagate in the deep convolutional spiking neural network, and the expected value of spiking will decrease as the number of layers increases. This phenomenon of spike disappearance will seriously affect the application of deep spiking neural network in reinforcement learning, and the performance of Spike-DQN is reduced, making it difficult to train. We use the membrane potential normalization method to increase the activity of neurons and perform layer normalization on the postsynaptic potential (PSP).
class PopNorm(Module):
def reset_parameters(self) -> None:
if self.affine:
nn.init.constant_(self.weight, self.threshold-self.v_reset)
nn.init.constant_(self.bias, self.v_reset)
def forward(self, input: Tensor) -> Tensor:
out = F.layer_norm(
input, self.normalized_shape, self.weight, self.bias, self.eps)
return out
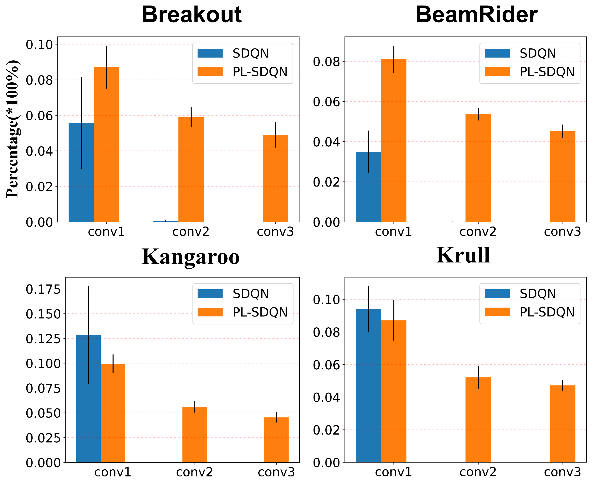
The proposed spiking value network PL-SDQN based on the layer normalization method of membrane potential enables the spike signal to be well transmitted to the deep layer of the network. The following figure statistics the spikes firing rate of different convolutional layers:
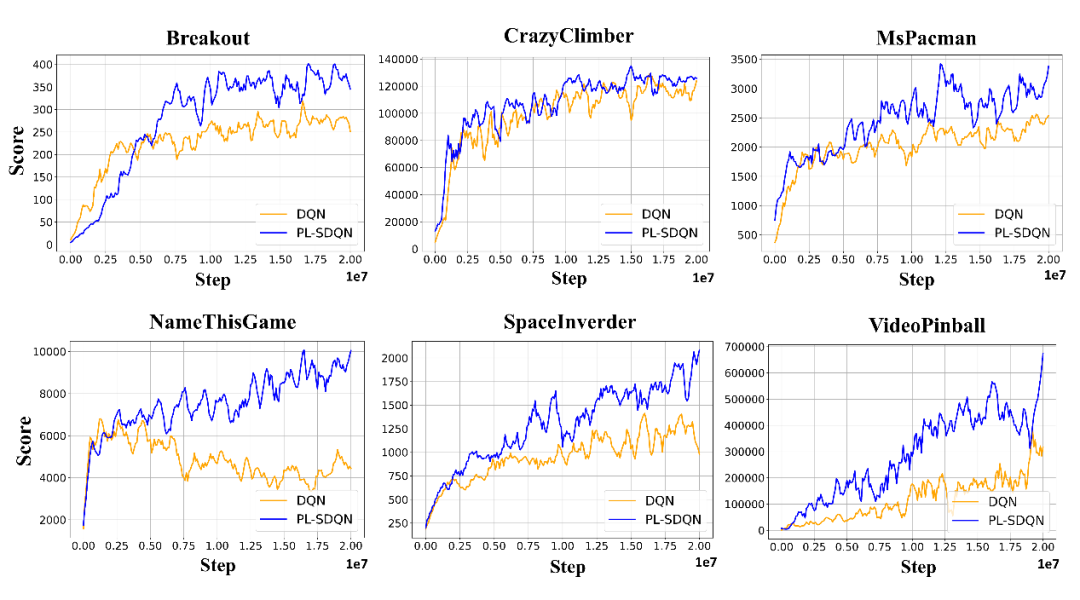
PL-SDQN achieves better performance than vanilla DQN.
Code Link:
https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/decision_making/RL/sdqn
Related papers:
@ARTICLE{sun2022,
AUTHOR={Sun, Yinqian and Zeng, Yi and Li, Yang},
TITLE={Solving the spike feature information vanishing problem in spiking deep Q network with potential based normalization},
JOURNAL={Frontiers in Neuroscience},
VOLUME={16},
YEAR={2022},
URL={https://www.frontiersin.org/articles/10.3389/fnins.2022.953368},
DOI={10.3389/fnins.2022.953368},
ISSN={1662-453X},
}
@misc{https://doi.org/10.48550/arxiv.2207.08533,
doi = {10.48550/ARXIV.2207.08533},
url = {https://arxiv.org/abs/2207.08533},
author = {Zeng, Yi and Zhao, Dongcheng and Zhao, Feifei and Shen, Guobin and Dong, Yiting and Lu, Enmeng and Zhang, Qian and Sun, Yinqian and Liang, Qian and Zhao, Yuxuan and Zhao, Zhuoya and Fang, Hongjian and Wang, Yuwei and Li, Yang and Liu, Xin and Du, Chengcheng and Kong, Qingqun and Ruan, Zizhe and Bi, Weida},
title = {BrainCog: A Spiking Neural Network based Brain-inspired Cognitive Intelligence Engine for Brain-inspired AI and Brain Simulation},
publisher = {arXiv},
year = {2022},
}